Midterm support and development of Mobile Applications
In this article you will learn about midterm support an development from mobile applications
Code legacy, project member fluctuation, frequent code changes. Terms which make longterm projects and quality assurance challenging, this also applies to software. Now, with an iPhone app in store where the first line of code was written in Nov. 2013, we came across some fairly common issues in software development and everyday’s business.
- Personal fluctuation – One of the crucial project members left the team and took undocumented knowledge with him
- Knowledge base increases – One is aware of more performant approaches to implemented solutions
- Deprecation – Parts of code are outdated nowadays and there are easier and also more performant solutions due to new firmware and OS updates
After a waterfall development go live, we shifted to an agile development process and the coherent epic and feature request management. We had the choice to either increase code stability based on established code parts or re-invent the „new feature wheel“ and refactor huge chunks of code altogether. I’d like to give you a short glance at the involved code architecture to promote the approach of code refactoring. Even if the regarded code is handling an application’s core logic and functionality.
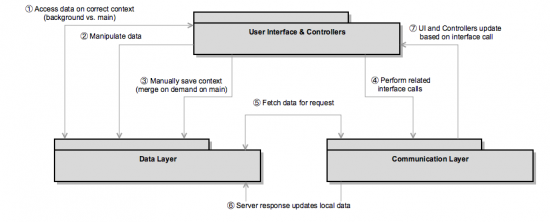
Motivation to update this approach
- No more Core Data because
- Data model hierarchy results in one single table for all sub class objects, thus resulting in huge amount of entries in one single data table
- Unit tests and especially integration tests which were related to data base transactions were highly related to each other – because of the core data background
- Easily encryptable database, so we can use one data source also for encrypted data, which was currently stored in a different way or for upcoming sensible data in the future
- Direct key-value observation on core data objects is only established using a work around (listen to object save notifications).
- The controller had to have control of the object and the related saving operations of the object’s entity.
- Key value observation should trigger the persistency of the object, in order to prevent the controller from becoming active again after manipulating an objects property.
- Value modification should be used to directly trigger an interface call to have a highly synchronised backend (also across devices). The controller should not decide what kind of web request is required to update an object and its related properties in the backend.
In particular, the last motivation point was a result of an internal code auditing in February. The auditing was held in respect to project member fluctuation, code legacy, code deprecations due to old libraries being used as well as preparing to meet the expectations of users and the customer for the upcoming years.
Refactored Architecture
The planned target architecture has proved itself in several other projects already, the steps in between are design decisions made especially for the iOS app.
The advantage of the new approach: the data layer and in particular the communication layer are supposed to be loosely coupled with the application, visible for the user. Neither do we want to have too much business logic of CRUD-operations in the controller classes or a differentiation of REST-Calls in them. The idea: The data and communication layers form a separate level of logic, accessed through a well-defined set of public methods. In short: The business logic will be packed in a library, which will replace the existing heterogenous source code.
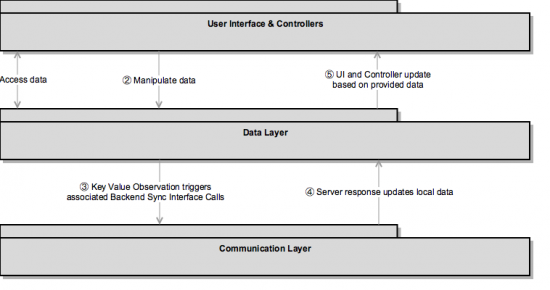
Success ?
Definitely! We had a testing phase of 6 weeks (with 8 professional testers) and found 22 related issues, out of those only 3 were classified as major or critical. Even two of those three major/critical issues were found and fixed in the first days of testing. The new library has 14’000 lines of code, not counting the lines of code in the existing application container which accesses the library. We developed the source code test driven, to ensure a reliable base for the existing project. The benefit for this was besides of the good interface documentation and specification also the well-known set of scenarios of data manipulation and data correlation.
A small statistic to prove the overwhelming success: even very optimistic „Bug to code ratio“ estimations expect three defects per 1’000 lines of code (related to especially quality-driven software development like space shuttle programs etc.), while pessimistic forecasts usually expect 15 to 50 bugs per 1’000 lines of code.
We are thus (as far as we know after multiple weeks of extensive testing) on a rate of less than 2 bugs per 1’000 lines of code! And even with possibly unknown and hidden bugs we are still very satisfied with this result.
### Tech How To ON ###
For all of those, interested in how to implement such a refactoring process, I have attached a step by step guide.
Refactoring Process
How would you proceed with an app specific source code (excluding other libraries etc.) of 60.000 lines of code, roughly a document of 1.300 pages?
Find & Replace?
„Remove old code and replace it with new code“
Yeah, that’s pretty much it:
- Identify classes, functions or properties to be replaced
- Map classes and methods to new architecture
- Note down the ones that will be obsolete due to architectural impact
- Provide neat (compiler- & build-friendly) function and property changes
- Add Library to the project
- Remove old code from the project
- Make use of our replacement methodology and finish refactoring your code base
1) Identify classes, functions or properties to be replaced
We know the old code parts are related to the Data Layer and Communication Layer, thus we pretty fast had the folders and classes listed, which shall be replaced with the new library. But even easier for this was the fact of a well-defined interface specification, so we were also aware of the detailed functionality of the different classes, which data is required and which is optional.
Besides obvious data model or rest interface classes, we also had to identify delegate methods, helper functions and other code fragments. Altogether this is dividable in four distinct categories:
Classes, functions or properties reusable with the exact same naming (easier for integrating the library and will reduce the necessity to touch working code parts)
Classes, functions or properties reusable with different parameters or return types (I want to show you a way how to solve this issue in a pretty convenient way in step 2, because this would not require a change at a calling class at all, if everything was done right)
Not reusable at all. We hardly encountered this case, but this might happen due to architectural changes. If so. Be prepared to have a substitution for this code in place, if it was really required. – see Step 3
Classes, functions or properties reusable with a different naming (a mapping from the old function to the new function should be provided, so the replacement process is easier) – see Step 4
2) Map classes and methods to new architecture
Of course one has a rough overview what kind of class or pattern will be replaced by the new approach. Still, I wanted to mention a compiler friendly approach, especially with respect to Step 2.3: We have to map old value types to new ones. Imagine a project structure, where required classes were simply deleted but the class types would still be used in functions. Result would be pretty obvious: Compiler errors.
With the LLVM compiler structure we provided a nice approach to „map“ the old class types to the new ones by defining simple macros:
#define oldClassModel newClassModel
The Compiler would not be aware of the old class type (thisIsMyOldClass), as this one would be mapped by a macro, which itself simply provides a reference to the new class type (newClassModel).
Of course, one would still have to replace all „hard coded“ strings, which contain this „oldClassModel“ – mainly, the class imports.
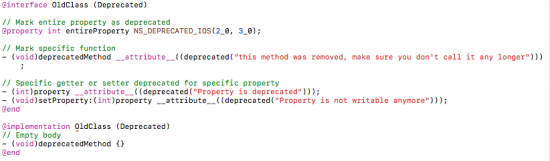
3) Note down the ones that will be obsolete due to architectural impact
We took special care of classes, functions and properties, which will be removed from the code base completely – in a special way.
We had a separate section for these deprecated elements.
Classes
We simply mapped the deprecated classes to the base class NSObject, which is one of the primary root classes in Cocoa.
Functions & Properties
Functions were added to a specific category to the older class and flagged to be deprecated. Then an empty function body was implemented and we always returned (in case of return types) nil/null or 0
To achieve that, we can use use Clang Language Extensions to inform for better maintenance about our custom adjustments.
Of course we could also keep the old code. But: why should we even bother to copy the old code, if we could simply inform the compiler and thus our developers to not use the old method anymore?
For Properties we had a similar approach
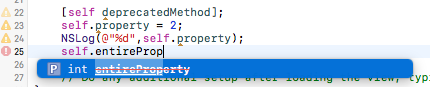
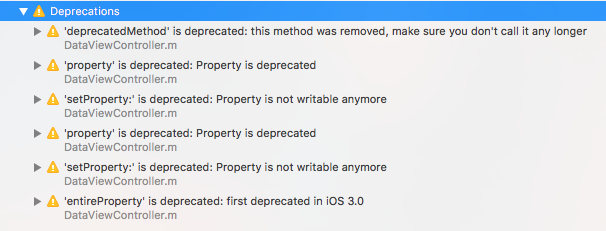
4) Provide neat (compiler- & build-friendly) code changes
The mapping will shortly be described as function attribute, so the compiler is aware of this warning (see Step 3 for this).
Furthermore, the code documentation will help developers to display additional information about this deprecated method and how to proceed.
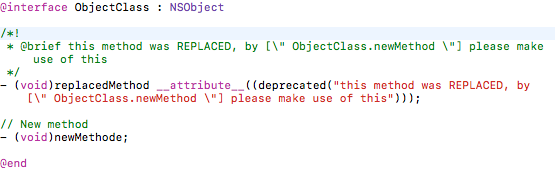
As a result of the brief code documentation, the IDE recommends an alternative to the deprecated function to the software developer.

5) Add library to the project
Well, before you remove your old working code, make sure the library you want to use fits into the project. Fix library reference issues before removing the old code parts, else there will be a mess of compiler and project errors. As we did not implement a class twice but used instead categories for deprecated code functions or class mappers, we should not run into trouble of having a duplicate interface definition.
6) Remove old code from the project
Enjoy and delete all the old classes and functions, you had identified in step 1 and meanwhile.
7) Make use of our replacement methodology and finish refactoring your code base
Don’t worry. The project should still be compilable with a lot of new warnings, which we produced on our own. The software itself will pretty sure not work as intended yet (empty functions replaced the old code). We still need to make use of our compiler hints regarding the deprecated function calls and their replaced methods. Go through these 1’000 warnings and run your project again. Whether you do replace this from top to bottom or by refactoring specific code parts first (e.g. object model first, then communication methods, etc.) or by making use of your user stories in the application (start with registration process, go on with login, etc.) is in the end your decision.
If you want to parallelise testing, I would recommend the way to refactor user story related issues first. If you want to get your work done, I would recommend refactoring code parts of the same type (e.g. the object model related parts first).





